

In today’s Internet, it takes specific skills to efficiently find the “Data You Want” inside of the “Data You’re Given”. I was reminded of this the other day watching a colleague struggle through data collection, clicking buttons and getting diverted by advertisements that look like more buttons.
If you want specific data from a webpage, here’s a snippet of code that will do it for you using urllib and Regex. This was written to collect bulk data from the European Bioinformatics Institute (EBI) PDBePISA website; download the full, functional code as an attachment here. It was written to be executed using Python 2.7 — try the web app-based training at Codecademy.com if you’d like a great and easy crash-course on programming!
# The snippet of code below does not run; it is modified for
# readability. Download the attachment for the full code!
import urllib, urllib2, re
# …
for item in pdb_list:
#
#Build URL call, refer to URLLIB and URLLIB2 documentation”
#
url = “http://www.ebi.ac.uk/msd-srv/pisa/cgi-bin/piserver”
values = { ‘page_key’ : ‘sform_page’,
‘action_key’ : ‘act_submit_pdb’,
‘dir_key’ : ‘632-4B-2AF’,
‘session_point’ : ‘2’,
‘radio_sf_session_type’ : ‘id_sf_dbsearch’,
‘radio_source’ : ‘id_pdbentry’,
‘entry0’ : item,
‘entry1’ : item,
‘edt_pdbcode’ : item }
post = urllib.urlencode(values)
request = urllib2.Request(url,post)
response = urllib2.urlopen(request)
html = response.read()
The above lines are used to build the POST request. Read about “HTML Forms” to get more background on this – this is how a website receives information from the text boxes when you click on the “Submit” button. Sometimes, you can leave all the values blank and just open a URL.
The result is a variable html that contains a long string of HTML code…
html = ‘\n<!doctype html>\n<!– paulirish.com/2008/conditional-stylesheets-vs-css-hacks-answer-neither/ –>\n<!–[if lt IE 7]> <html class=”no-js ie6 oldie” lang=”en”> <![endif]–>\n<!–[if IE 7]…
Next, I need to parse the string for the information I want. I use Regex for this:
#
#Use REGULAR EXPRESSION (REGEX) to find the text
#and values that we want
#
search = re.findall(r‘Analysis: <strong><input style=”color:blue;bgcolor:white; border:0;” size=”64″ value=”(.*)” …’,html)
if len(search)==1:
analysis = search[0]
print item +“:\tAnalysis:\t\t”+analysis
else:
analysis = “???”
print item+“: \t*Error finding Analysis for “+item
I won’t go into the details of using RegEx, but you can read Regular-Expressions.info and download Kodos (Windows) to play with it. As an alternative, save the entire html string to a log file or check to see if a substring is inside the larger string.
Once you have the above working, you can really empower your computer to do your job for you:
- Run the program on a timer using Crontab or Windows Scheduled Tasks, have it “watch” a webpage for you.
- Use it to record information, such as license usage, for generating reports and graphs later.
- Alert yourself by email or SMS when a trigger appears on a target webpage.
Remember to download the attached batch_pisa_v2.py file to modify or run on your own. If you master this, I’m certain that you’ll be able to save yourself hours on a regular basis and, even more importantly, you’ll be able to provide creative solutions even after others have conceded defeat!
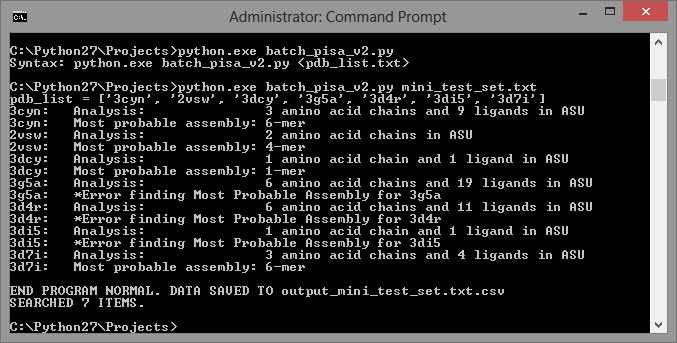
I’ve already told you that no problem in unsolvable – next, I’ll show you how to solve your problems faster.
Next Steps:
- Contact SPK and Associates to see how we can help your organization with our ALM, PLM, and Engineering Tools Support services.
- Read our White Papers & Case Studies for examples of how SPK leverages technology to advance engineering and business for our clients.
Edwin Chung
Client Program Manager, SPK & Associates



