

What are Procedures in CloudBees SDA?
In CloudBees SDA, procedures are the basis for reusable code. Any engineer familiar with setting up CD pipelines knows the irritation of re-coding the same task in a multitude of different ways for different teams. With procedures, this can be done once with a limited number of inputs and outputs, then simply dragged-and-dropped right where it needs to be.
How do I use CloudBees SDA Procedures?
Setting up a procedure is a simple process. At its simplest, all you need is a working resource and some kind of task to accomplish. For example, let’s say we want to set up a procedure to return the output of an ls command. We’ll need an input parameter, output parameter, and a command to run.
Open up the procedures tab and create a new one. In my example we’ll just use the default project and local resource.
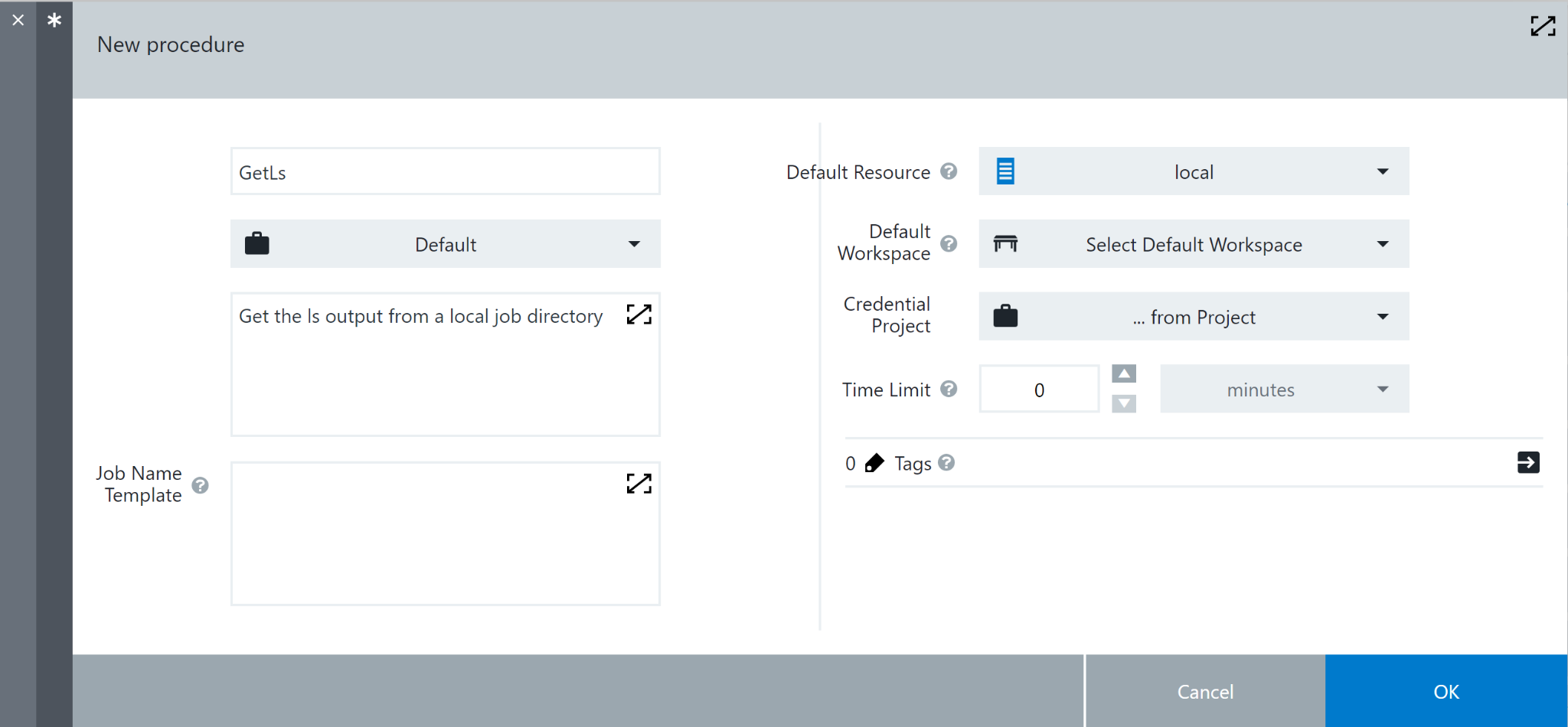
From there, we need to set up the input and output parameters. The menu in the upper right has both of these, open it and select “parameters”, then create a new input parameter. We’ll call this one “path”, with a label “Path”, and click the checkbox to mark it as not required. This is a text entry parameter, and should be optional. Hit ok and select output parameters, then create a new one. We’ll call this one “ls”. Think of these two parameters as the external input and output pipes when this procedure is run.
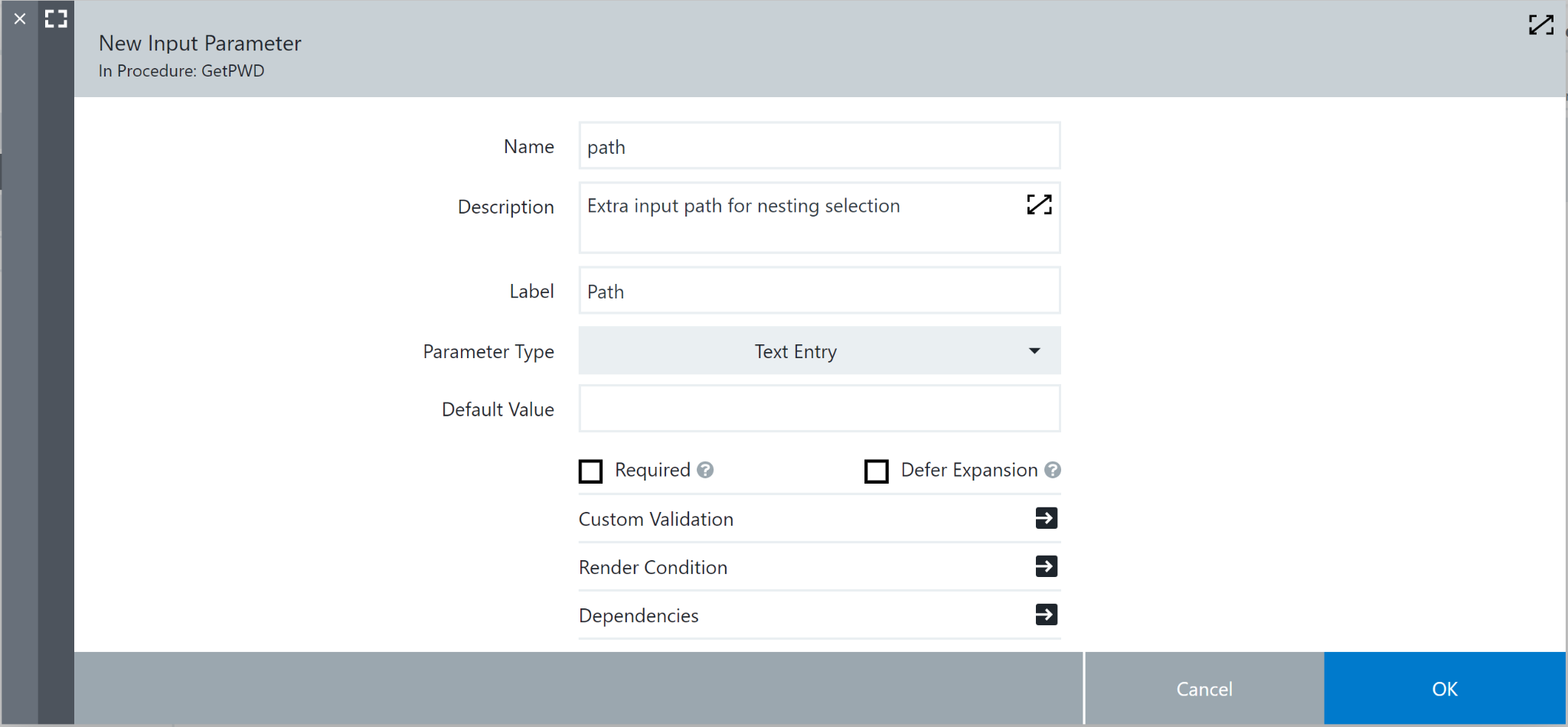
Hit ok, then create a new step in the main window. This will be the task that does the actual work, we’ll call it “GetLs”. Go to the definition of this step and ensure it’s a command. From there, we need to put “ec-groovy” in the shell, so it will run in the groovy console. The final step is to give it a command to run. Here is the command we will use:
____________________________________________
import com.electriccloud.client.groovy.ElectricFlow import com.electriccloud.client.groovy.apis.model.* ElectricFlow ef = new ElectricFlow() //set command to run def command = "ls -al " + "$[path]" //execute command and get output def ls = command.execute().text //log output println(ls) //set result to output parameter def result = ef.setOutputParameter(outputParameterName: 'ls', value: ls)
____________________________________________
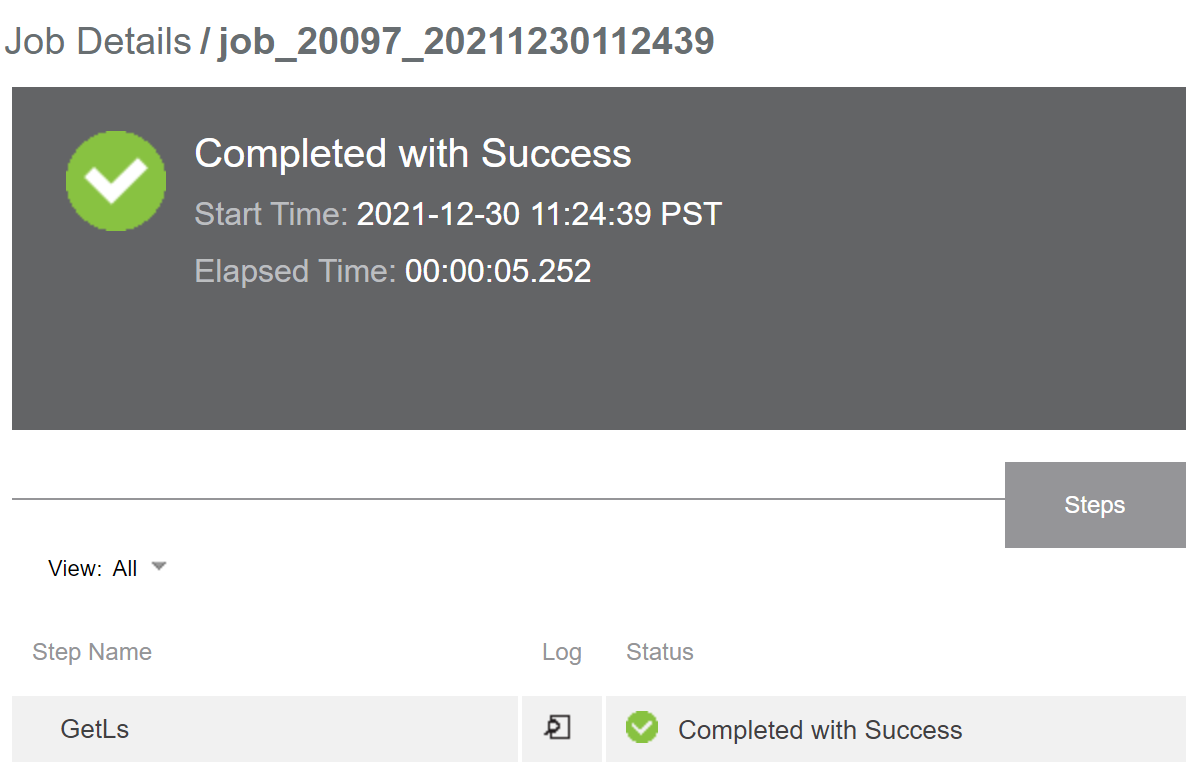
Input this into the command line and click OK. From there, you can run the procedure with the play button in the upper-right corner. The procedure will ask for the optional input parameter and run the command, then kick the output to the output parameter. Clicking on the task and log will show the results.
Use in a pipeline
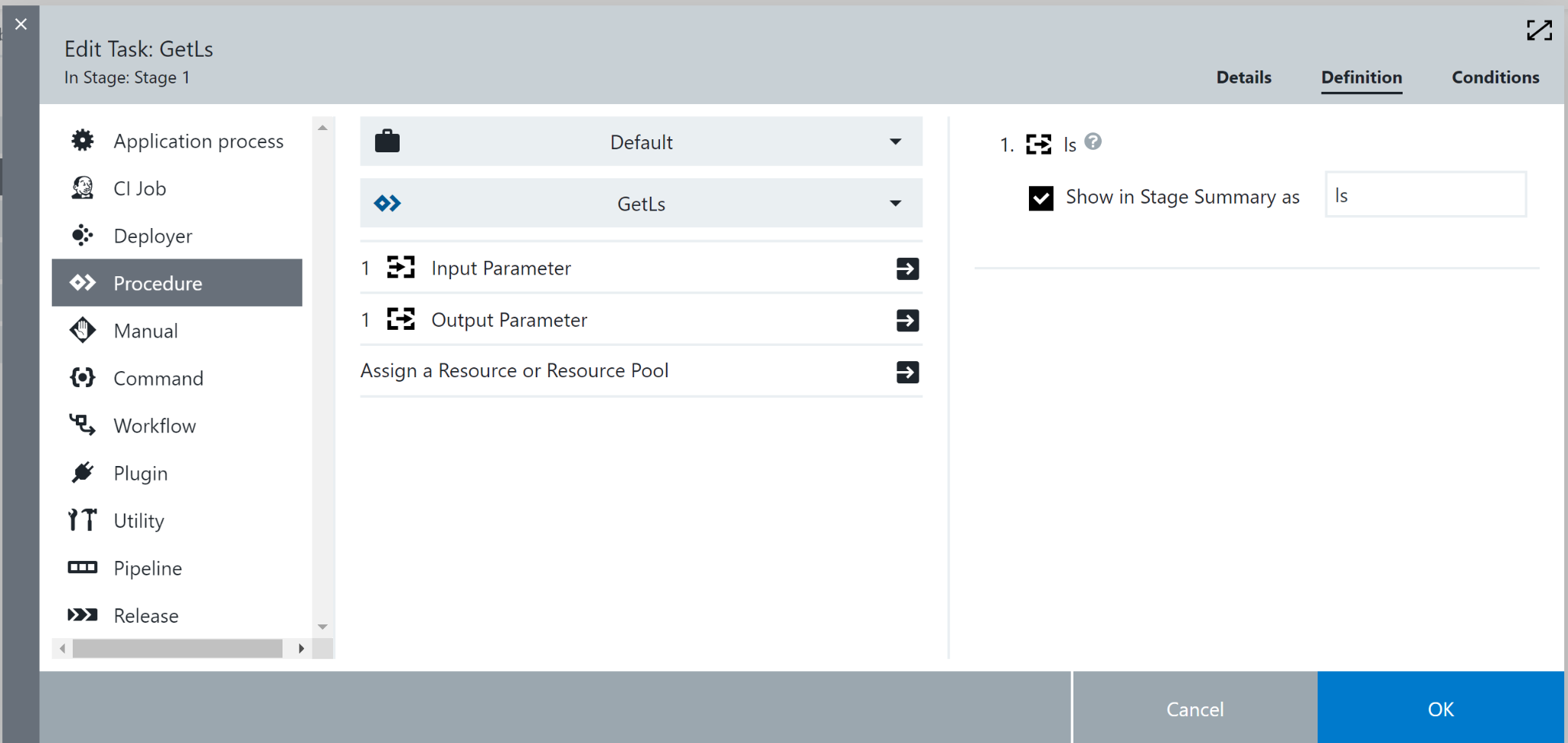
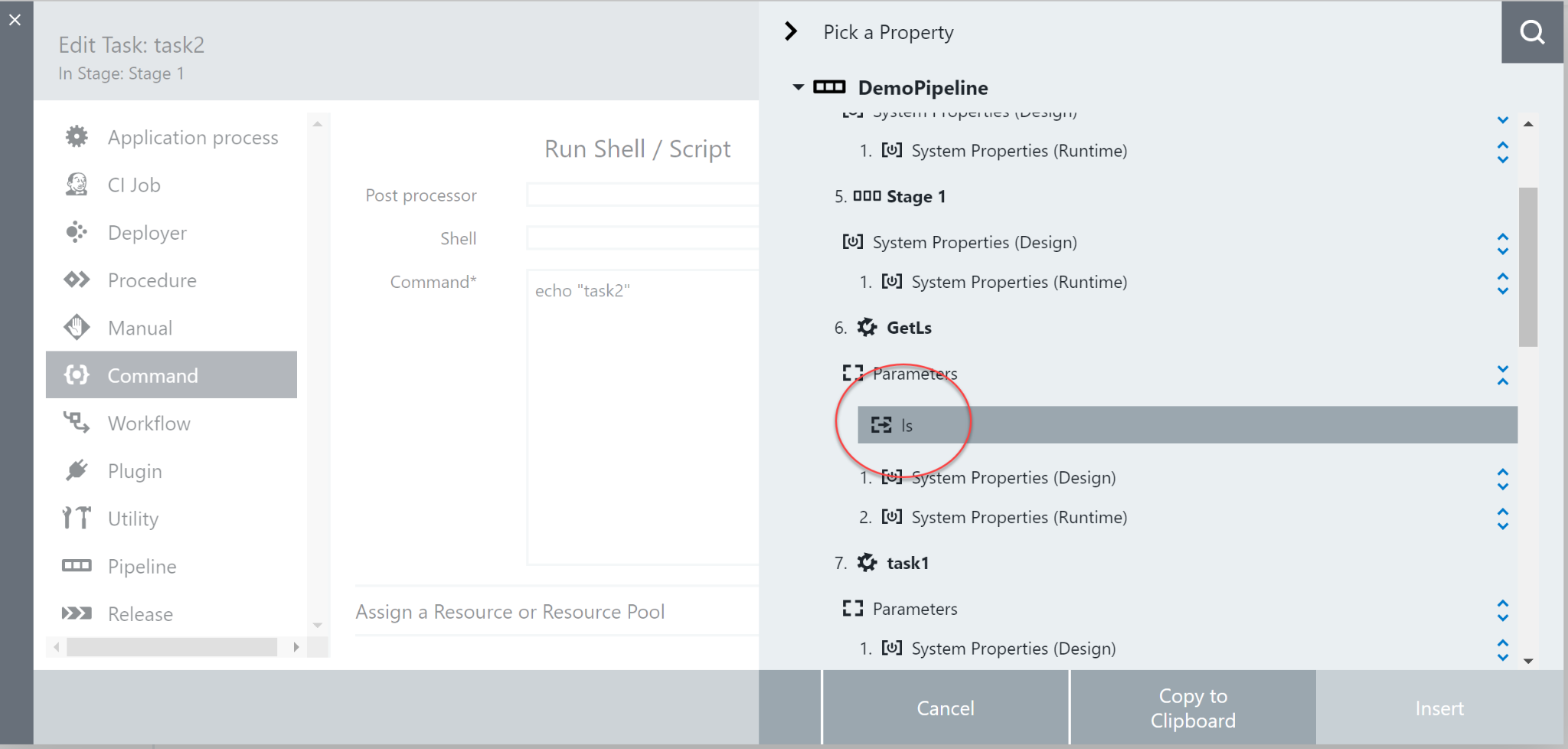
So now we’ve got a procedure that does a task on its own, how can we deploy this from within a pipeline context? Luckily, this is a very simple task. Open up the pipeline that will use this procedure and create a new task. Select procedure, and navigate to the “GetLs” procedure we just wrote. From here you can change the input path and how the output parameter can be stored in the stage summary. Please note that the input parameter can be a static input, or another parameter/property updated dynamically.
Run the pipeline normally and you’ll be able to see the output on the task run screen. To use this information in other pipeline tasks, you can use the property picker (upper-right corner of any command screen) to select the output parameter and easily get the necessary path to use it.
Conclusion
In general, if I find myself performing any task more than once in SDA, I will immediately look to how I could use it in a procedure instead. It’s a powerful way to simplify code, increase readability, and improve consistency all at once. With these techniques at your disposal, you’ll be able to create extensible tasks that other members of your team can use without your input.



