
What is a Continuous Integration Pipeline?
The purpose of a continuous integration pipeline is to allow teams to constantly integrate and build software updates in order to quicken release cycles, lower costs, and reduce risks.
In a simple implementation of a continuous integration pipeline, you would typically create a chain of procedures that perform the same set of operations on the supplied input. This provides a build process that is well-defined, repeatable, consistent, and which functions as the foundation for deploying quality software.
But many CI systems are more complex. They often must accept new or unique inputs, or dynamically adapt to the types of input provided. Within CloudBees CD, you can achieve more flexibility through the use of procedure parameters, subprocedures, and run conditions.
Example of a Flexible Pipeline
Suppose, for instance, that you have two modules you need to build as part of your development process. In this case, you only wish to build a module if it has code changes. A basic approach to solve this would be:
- create a procedure for each of the modules,
- append each as a sub-procedure to the larger build process,
- and set a run condition on each to only execute if a flag is set (see Fig. 1).
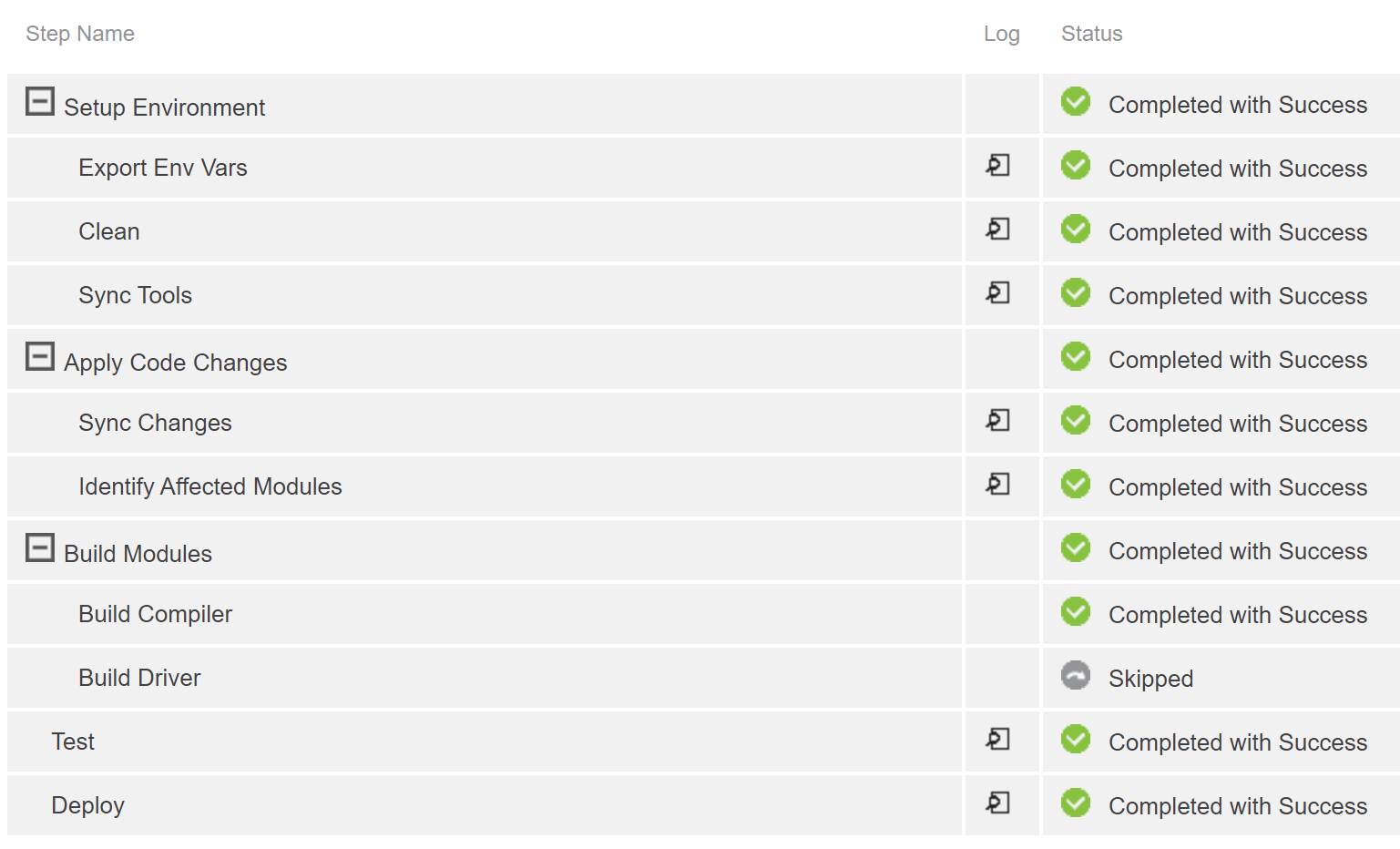 Figure 1 shows statically defined steps that are either executed or skipped based on flags.
Figure 1 shows statically defined steps that are either executed or skipped based on flags.
A More Advanced, Flexible Pipeline
A slightly more advanced method would be to create a single generalized procedure that contains the logic necessary to build the correct object, given the appropriate parameters. Done well, this kind of procedure could handle modules it has never seen before, making extension painless. However, the problem with this continuous integration approach is that now you’ve hidden the process inside a black box, and you’ve removed the easy access to running job steps in parallel afforded by CD (see Fig. 2).
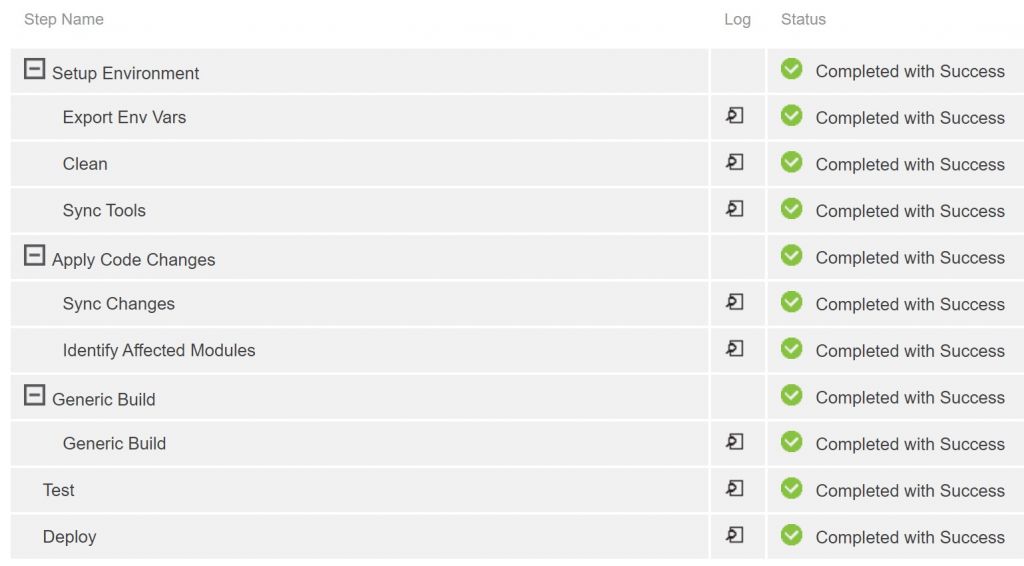
(Figure 2)
A Better Way
Better yet is a continuous integration procedure that dynamically appends only the steps necessary for the current build at runtime. Doing this removes the clutter associated with skipping unnecessary procedures, while providing flexibility, visibility and access to running activities in parallel. Fortunately, we can do this using the createJobStep API method (see Fig 3).
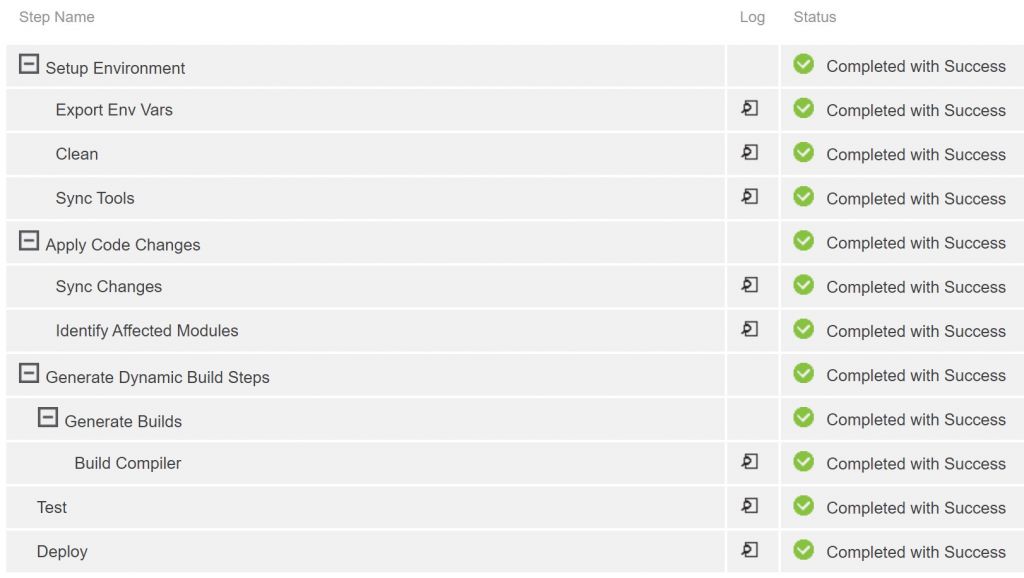
Figure 3
With createJobStep you have the ability to:
- define a completely new step, or
- select an existing procedure to append to a given job as a sub-procedure,
at run time.
To dynamically create a new step, you can simply call createJobStep and supply the “—command” argument with the code you want executed. Usually it’s best to supply a name for the generated step, otherwise it will default to a name consisting of the parent step and the jobstepID number. The good news is that you have complete control over every detail of the step you generate through a very thorough set of options, as shown below.
Usage: createJobStep
[–jobStepId <jobStepId>]
[–parentPath <parentPath>]
[–jobStepName <jobStepName>]
[–projectName <projectName>]
[–procedureName <procedureName>]
[–stepName <stepName>]
[–external <0|1|true|false>]
[–status <status>]
[–credential <credName>=<userName> [<credName>=<userName> …]]
[–description <description>]
[–credentialName <credentialName>]
[–resourceName <resourceName>]
[–command <command>]
[–subprocedure <subprocedure>]
[–subproject <subproject>]
[–workingDirectory <workingDirectory>]
[–timeLimit <timeLimit>]
[–timeLimitUnits <hours|minutes|seconds>]
[–postProcessor <postProcessor>]
[–parallel <0|1|true|false>]
[–logFileName <logFileName>]
[–actualParameter <var1>=<val1> [<var2>=<val2> …]]
[–exclusive <0|1|true|false>]
[–exclusiveMode <none|job|step|call>]
[–releaseExclusive <0|1|true|false>]
[–releaseMode <none|release|releaseToJob>]
[–alwaysRun <0|1|true|false>]
[–shell <shell>]
[–errorHandling <failProcedure|abortProcedure|abortProcedureNow|abortJob|abortJobNow|ignore>]
[–condition <condition>]
[–broadcast <0|1|true|false>]
[–workspaceName <workspaceName>]
[--precondition <precondition>]
Complex Builds
An additional benefit of createJobStep is how it opens the door for defining entire continuous integration build processes outside CD in configuration files. These files are easy for developers to read, modify, and place under version control. Then, you simply define a procedure to read in the configuration file and based on its contents, append the appropriate steps to the running build.
A major benefit of CD is the visibility it provides into the workings of these complex builds. You want to avoid the black box situation mentioned earlier because it makes it hard for new eyes to understand what’s happening and makes debugging trickier. You can do this by appending multiple, smaller steps rather than a single monolithic step that performs multiple tasks.
In terms of security, it should go without saying that you need to put in the appropriate safeguards.
Some applications are complex enough that it makes sense to have multiple varieties of prescribed runbooks based on what comes into the pipeline. For those, CloudBees CD can use the application framework to deploy code using predefined business logic. For example, if one application needs to deploy a .war file, and another needs to deploy a .zip, and both have multiple steps related to that deployment, a branching patchway can be set that will run one or the other based on input. (See Fig 4)
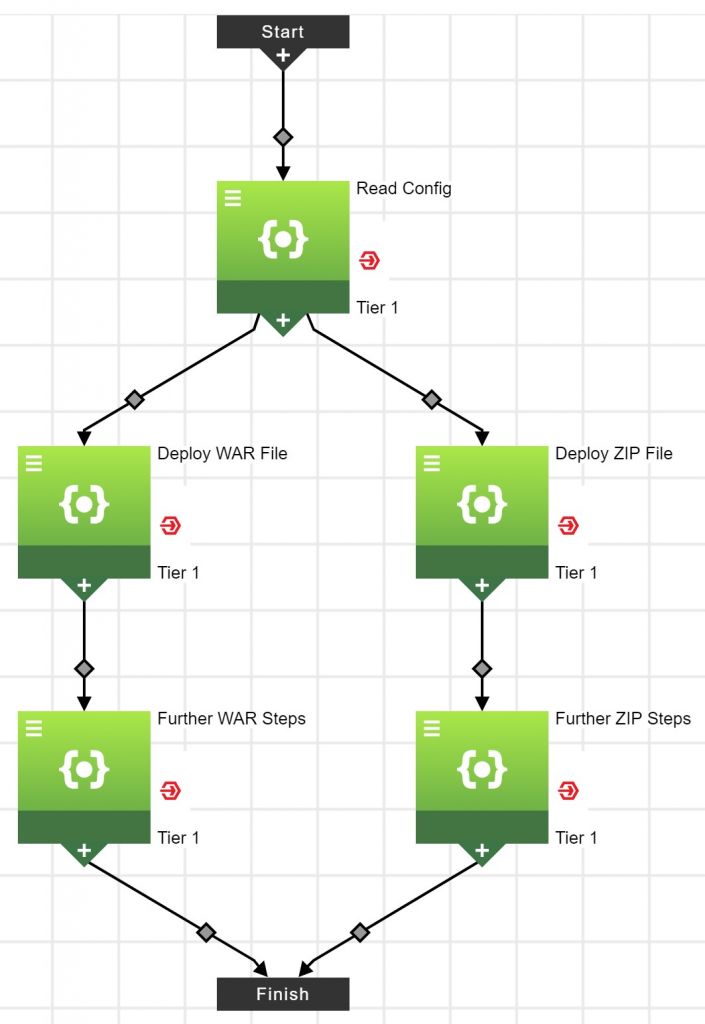
Figure 4
This continuous integration process looks complex, but using a branching pathway makes it clear exactly which steps are being run in sequence or parallel, and takes the headache out of figuring out what will run when. Ultimately, the goal of creating dynamic steps is to declutter and streamline builds to make them more intelligible and efficient. The createJobStep command is a very powerful tool to help achieve this end.
Next Steps:
- Contact SPK and Associates to see how we can help your organization with our DevOps, CloudBees CD, and Software Delivery Automation services.
- Read our White Papers & Case Studies for examples of how SPK leverages technology to advance engineering and business for our clients.



